

第1回 ロジカルレプリケーション
1. はじめに
PostgreSQLは、バージョン9.0からレプリケーション機能として「ストリーミングレプリケーション」をサポートしていますが、 バージョン10から新たに「ロジカルレプリケーション」が追加されました。ここでは、この2つのレプリケーションの違いや、ロジカルレプリケーションの設定方法などを理解していきましょう。
2. ストリーミングレプリケーションとロジカルレプリケーション
まずは、ストリーミングレプリケーションとロジカルレプリケーションの違いについて理解を深めていきましょう。

図1 ストリーミングレプリケーションとロジカルレプリケーションの仕組み
ストリーミングレプリケーションは、マスター側から全てのトランザクションログ(WAL)を転送し、スタンバイ側はWALを適用(リカバリ)します。WALにはデータベースの全ての変更情報が物理的なレベルで記載されています。このWALを適用することで、データベースクラスタの完全なコピーが作成できます。そのため、ストリーミングレプリケーションは負荷分散や、PacemakerなどのHAソフトと組み合わせて可用性を高めるために利用されています。ただし、WALをそのままリカバリするためPostgreSQLのメジャーバージョンや、OSのアーキテクチャが異なる場合は、実施不可となります。
ロジカルレプリケーションではWALに記載されている変更情報を論理的なレベルに変換(デコード)してから転送します。そのため、PostgreSQLのメジャーバージョンや、OSのアーキテクチャが異なる場合でも実施可能です。レプリケーションの上流側にパブリケーション、下流側にサブスクリプションを作成することで、レプリケーションの対象を制御することができます。具体的には、特定のテーブルのみレプリケーションすることや、INSERT・UPDATEはレプリケーションするがDELETEはしないなど、特定の操作のみレプリケーションすることも可能です。
この特徴を踏まえて、ロジカルレプリケーションは下記のような利用例が考えられます。
- 異なるメジャーバージョンのPostgreSQL間でレプリケーション
- 異なるOS(例えばLinuxからWindows)のPostgreSQL間でレプリケーション
- 分析目的で必要なデータを複数のデータベースから集めて、一つのデータベースに統合する
- 複数のデータベース間で、特定のテーブルのみを共有する
ただし、ロジカルレプリケーションには制約事項と注意事項がありますので、留意しましょう。
制約事項
レプリケーションされないコマンドとオブジェクトがあります。
コマンド:DDLコマンド ※PostgreSQL10はTRUNCATEコマンドもレプリケーションされません
オブジェクト:シーケンスデータ、ラージオブジェクト、通常のテーブル以外(ビュー、マテリアライズドビュー、パーティションのルートテーブルなど)
詳細はこちら
[https://www.postgresql.jp/document/11/html/logical-replication-restrictions.html]
注意事項
ロジカルレプリケーションはサブスクライバー側でも更新処理を実行できるようになりましたが、注意が必要です。
サブスクライバー側に到着したデータが一意性制約などの制約に違反すると、レプリケーションは停止します。これはコンフリクトと呼ばれ、コンフリクトは自動で解消されないため、ユーザによる手動の対応が必要となります。
詳細はこちら
[https://www.postgresql.jp/document/11/html/logical-replication-conflicts.html]
これまで説明したストリーミングレプリケーションとロジカルレプリケーションに関する比較を表1にまとめます。
ストリーミングレプリケーション |
ロジカルレプリケーション |
|
|---|---|---|
レプリケーションの方法 |
全てのWALをそのまま転送 |
WALをデコードして転送 |
レプリケーション対象 |
データベースクラスタ単位 |
データベース単位(テーブル、操作を指定可能) ※ただし、DDLコマンドと一部のオブジェクトがレプリケーションされない |
異なるメジャーバージョン間の動作 |
不可 |
可能 |
利用例 |
負荷分散、高可用性 |
|
スタンバイ側/サブスクライバー側の操作 |
参照のみ |
参照と更新が可能 ※コンフリクト(衝突)が発生する可能性がある |
3. 環境構築
ここからは実際に環境を使用して、ロジカルレプリケーションを設定し動作を確認するまでの一連の流れを確認していきます。
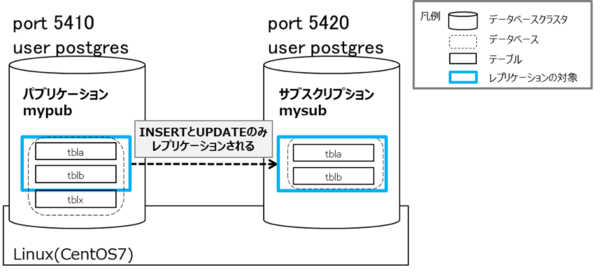
図2 環境の概要図
前提
この動作確認にはPostgreSQL11を使用します。
同一サーバ上にデータベースクラスタを二つ作成し、Portはそれぞれ5410,5420を利用しました。
作成するパブリケーションはmypub、サブスクリプションはmysubです。
パブリッシャー側に3テーブル tbla,tblb,tblx を作成しますが、ロジカルレプリケーションの対象テーブルは2テーブルtbla,tblbに制御します。レプリケーション対象の操作はINSERT,UPDATEに制御します。
設定事項
【パブリッシャー側の設定】
postgresql.confの設定
wal_levelはWALに書かれる情報量を[minimal、replica(デフォルト値)、logical]から選択できますが、ロジカルレプリケーションではlogicalに設定する必要があります。
任意のポート番号(5410)を記述します。 変更したパラメータを反映するには、PostgreSQLの再起動が必要となります。
データ準備
パブリッシャー側に”publisher”という名前のデータベースを作成します。
作成したデータベースに接続します。
テーブルの作成
データの投入
パブリケーションの作成
レプリケーションの対象テーブルをtblaとtblbに制御し、操作もINSERT,UPDATEに制御するようなパブリケーションを定義します。
このように、対象テーブルは複数指定可能です。なお、全テーブルを対象とする場合はFOR ALL TABLESで指定します。また、どの操作(INSERT、UPDATE、DELETE、TRUNCATE)をサブスクライバー側にレプリケーションするかを指定することも可能です。なお、defaultで全操作がレプリケーションされます。
作成したパブリケーションを確認します。
対象テーブルは下記コマンドで確認できます。tblaとtblbのみ対象となっています。
加えて、レプリケーション対象の操作がINSERT,UPDATEのみであることを、pubinsert, pubupdateがt(TRUE)となっていることから確認できます。
このようにパブリッシャー側で意図した設定が完了したことを確認ができたので、続いてサブスクライバー側の設定をします。
【サブスクライバー側の設定】
postgresql.confの設定
任意のポート番号(5420)を記述します。
変更したパラメータを反映するには、PostgreSQLの再起動が必要となります。
データ準備
サブスクライバー側には”subscriber”という名前のデータベースを作成します。
テーブルの作成
DDLはレプリケーションされないため、サブスクライバー側にあらかじめテーブルを作成する必要があります。
サブスクリプションの作成
サブスクリプションを定義します。このコマンドが完了した時点でロジカルレプリケーションが開始します。
作成したサブスクリプションを確認します。
以上で、ロジカルレプリケーションの設定は完了です。
4. 動作確認
【レプリケーション対象テーブルの確認】
サブスクライバー側に設定どおりに、tblaとtblbがレプリケーションされているかを確認します。
もちろん、tblxはレプリケーションされていません。
【レプリケーション対象操作の確認】
INSERT
パブリッシャー側に接続し、tblaに対してINSERTを実施します。
サブスクライバー側に接続し対象テーブル(tbla)を確認すると、INSERTされた値がレプリケーションされていることを確認できました。
DELETE
続いて、パブリッシャー側に接続し、tblaに対してDELETEを実施します。
サブスクライバー側に接続し対象テーブル(tbla)を確認すると、DELETEされた値はレプリケーションされておらず残っています。
このようにDELETE操作のレプリケーションを抑止することで、何が実現できるでしょうか。
たとえば、あなたがECサイトを開発しており、ユーザの購買分析のために購入履歴を長期的に残しておきたいというニーズがあると仮定しましょう。
ところが、購入履歴を長期的に残した場合、購入履歴を参照するクエリが長時間化する可能性があります。加えて、この長時間実行されるクエリにリソースが取られ、他のオンライン処理にまで性能影響を与えてしまう場合も考えられます。やはり購買分析をリアルタイムに行うのは難しいため、バッチ処理するしかない。そんな悩みがあった場合、このロジカルレプリケーションが有効かもしれません。
新たにサブスクライバー専用サーバを構築し、アプリケーション用データベース(パブリケーション)と分析用データベース(サブスクライバー)を作成します。そして、DELETE操作のレプリケーションを抑止すれば、パブリッシャー側はアプリケーションで必要な最新データだけ残して余分なデータ削除しても、サブスクライバー側は分析に必要なデータ全て保持することができます。そうすれば、“クエリの長時間化”や“その他オンラインにおける処理性能影響”という問題の解決に貢献できるはずです。
高橋 由佳(著者)/OSS-DB Gold認定者
2017年に株式会社NTTデータ入社。システム技術本部 デジタルテクノロジ推進室所属。 性能プロフェッショナルチーム「まかせいのう」で、システムの提案/設計から開発/運用までの各工程におけるパフォーマンス最適化・トラブルシューティング業務に従事。
鳥越 淳(監修)
2008年頃からオープンソースソフトウェアの技術調査や案件導入に従事。PostgreSQLについては、PGConf.ASIA,PostgresConf USなどに登壇。共著に『PostgreSQL徹底入門 第4版』(翔泳社)がある。
