前回はパーティショニングの意義や、トリガーとテーブルの継承などを利用した従来のパーティショニングとバージョン10で導入された宣言的パーティショニングを比較しました。
今回は宣言的パーティショニングがバージョン11, 12でどのような進化を遂げたのかを概観します。
1. 機能面での向上
(1) デフォルトパーティション(バージョン11以降)
バージョン10では、マッチするパーティションがない場合、以下の例のようにエラーを返すしかありませんでした。
-- 親テーブル定義
(PG10)=# CREATE TABLE japan (region text, spot text) PARTITION BY LIST (region);
-- 子テーブル定義
(PG10)=# CREATE TABLE tohoku PARTITION OF japan FOR VALUES IN ('東北');
(PG10)=# CREATE TABLE kantou PARTITION OF japan FOR VALUES IN ('関東');
(PG10)=# CREATE TABLE kansai PARTITION OF japan FOR VALUES IN ('関西');
(PG10)=# CREATE TABLE chubu PARTITION OF japan FOR VALUES IN ('中部');
-- マッチするパーティションがない場合エラー
(PG10)=# INSERT INTO japan VALUES ('小笠原村', '沖ノ鳥島');
ERROR: no partition of relation "japan" found for row
DETAIL: Partition key of the failing row contains
(region) = (小笠原村).
バージョン11以降では、マッチするパーティションがない場合に利用されるパーティション(デフォルトパーティション)を作成できます。以下の例では、othersという名称のデフォルトパーティションを作成しています。
-- 親テーブル定義
(PG12)=# CREATE TABLE japan (region text PRIMARY KEY, spot text) PARTITION BY LIST (region);
-- パーティション定義
(PG12)=# CREATE TABLE tohoku PARTITION OF japan FOR VALUES IN ('東北');
(PG12)=# CREATE TABLE kantou PARTITION OF japan FOR VALUES IN ('関東');
(PG12)=# CREATE TABLE kansai PARTITION OF japan FOR VALUES IN ('関西');
(PG12)=# CREATE TABLE chubu PARTITION OF japan FOR VALUES IN ('中部');
-- デフォルトパーティションを作成しない場合、バージョン10同様エラーとなる
(PG12)=# INSERT INTO japan VALUES ('小笠原村', '沖ノ鳥島');
ERROR: no partition of relation "japan" found for row
DETAIL: Partition key of the failing row contains (region) = (小笠原村).
-- デフォルトパーティションを作成
(PG12)=# CREATE TABLE others PARTITION OF japan DEFAULT;
CREATE TABLE
(PG12)=# INSERT INTO japan VALUES ('小笠原村', '沖ノ鳥島');
INSERT 0 1
-- パーティションjapanに挿入されたことを確認
(PG12)=# SELECT * FROM japan;
region | spot
----------+----------
小笠原村 | 沖ノ鳥島
-- デフォルトパーティションothersに挿入されたことを確認
(PG12)=# SELECT * FROM others;
region | spot
----------+------------
沖ノ鳥島 | 小笠原村
なお、デフォルトパーティションに格納されているレコードとパーティションキーがマッチするパーティションを後から追加しようとすると、エラーになる点は注意しましょう。
(PG12)=# CREATE TABLE ogasawaramura PARTITION OF japan FOR VALUES IN ('小笠原村');
ERROR: updated partition constraint for default partition "others" would be violated by some row
(2)パーティション間でのデータ移動(バージョン11以降)
バージョン10では、パーティションをまたがるデータの移動はエラーとなってしまいました。
たとえば、以下の例では青森県のデータを誤ってregion’関東’に挿入したため、regionを’東北’に修正するUPDATE文を実行していますが、失敗します。このためバージョン10では、このような処理を実現するためにDELETE文とINSERT文を発行する必要がありました。
(PG10)=# INSERT INTO japan VALUES ('関東', '青森県');
(PG10)=# UPDATE japan SET region = '東北' WHERE spot = '青森県';
ERROR: new row for relation "kantou" violates partition constraint
DETAIL: Failing row contains (東北, 青森県).
バージョン11以降では、UPDATE文による更新が可能になりました。
(PG12)=# INSERT INTO japan VALUES ('関東', '青森県');
(PG12)=# UPDATE japan SET region = '東北' WHERE spot = '青森県';
UPDATE 1
-- 東北パーティションに更新されたことを確認
(PG12)=# SELECT * FROM tohoku;
region | spot
--------+--------
東北 |青森県
デフォルトパーティションからの移動も可能です。よく考えると小笠原村は東京都、東京都は関東地方なので、沖ノ鳥島のregionを関東に更新してみます。
(PG12)=# UPDATE japan SET region = '関東' WHERE spot = '沖ノ鳥島';
-- 関東パーティションに更新されたことを確認
(PG12)=# SELECT * FROM kantou;
region | spot
--------+----------
関東 | 沖ノ鳥島
(3)パーティションテーブルに対する外部キー制約(バージョン11以降)
バージョン10まではパーティションテーブルに外部キー制約をつけることはできませんでした。このため、以下のようなDDLはエラーとなりました。
(PG10)=# CREATE TABLE customers (id INT PRIMARY KEY, name text);
(PG10)=# CREATE TABLE orders (id INT, custmer_id INT REFERENCES customers(id), date DATE) PARTITION BY
RANGE (date);
ERROR: foreign key constraints are not supported on partitioned tables
バージョン11以降ではパーティションテーブルへも通常のテーブル同様外部キー制約をつけられるようになりました。
(PG12)=# CREATE TABLE customers (id INT PRIMARY KEY, name text);
CREATE TABLE
(PG12)=# CREATE TABLE orders (id INT, custmer_id INT REFERENCES customers(id), date DATE) PARTITION BY
RANGE (date);
CREATE TABLE
(4)パーティションテーブルに対する外部キー参照(バージョン12以降)
バージョン11ではパーティションテーブルへの外部キー制約の付与は可能になりましたが、その逆にパーティションテーブルに対する外部キー参照はできませんでした。
(PG11)=# CREATE TABLE customers (id INT PRIMARY KEY , name text) PARTITION BY RANGE(id);
(PG11)=# CREATE TABLE orders (id INT, custmer_id INT REFERENCES customers(id), date DATE);
ERROR: cannot reference partitioned table “customers
バージョン12ではこの制約も取り除かれました。
(PG12)=# CREATE TABLE customers (id INT PRIMARY KEY , name text) PARTITION BY RANGE(id);
(PG12)=# CREATE TABLE orders (id INT, custmer_id INT REFERENCES customers(id), date DATE);
CREATE TABLE
このようにバージョン10では宣言的パーティショニング固有の制約により不便な思いをすることもありましたが、バージョン12では多くが改善され、パーティションテーブルを通常のテーブルのように操作できるようになっています。
2. 性能面での向上
パーティションテーブルへのクエリの性能は11、12いずれのバージョンでも大きく改善されています。これらの改善の多くはクエリを書き換えるなどの労力を払うことなく、 PostgreSQLをバージョンアップするだけでその恩恵を受けることができます(※)。
※ 具体的には、パーティションプルーニングの性能向上、実行時のパーティションプルーニング、パーティション数に対するスケーラビリティなど基本的な性能が向上しています。これらの詳細について興味がある方は、参考資料の(2),(4)を読んでみることをおすすめします。
本コラムでは、利用するためにパラメータ変更が必要なものを取り上げます。
(1)パーティションワイズ結合
パーティションワイズ結合は、同じパーティションを持つパーティションテーブルをパーティションキーを利用して等価結合する際に、まず対応するパーティション同士を結合することで、効率よくクエリを実行する仕組みです。
バージョン10までのPostgreSQLでは、同じパーティション境界を持つパーティションテーブルの結合でも、通常のテーブルと同じように大きな2つのテーブルを作ってそれらを結合していました。
図1
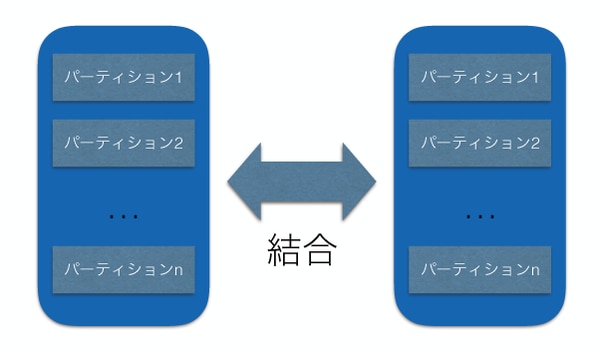
しかしながら、パーティション境界が異なる場合、例えばハッシュ結合する場合に、異なる剰余のパーティションを結合してもマッチするレコードがないのは明白です。
図2
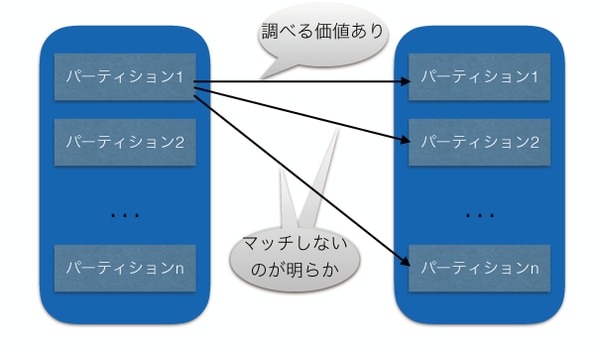
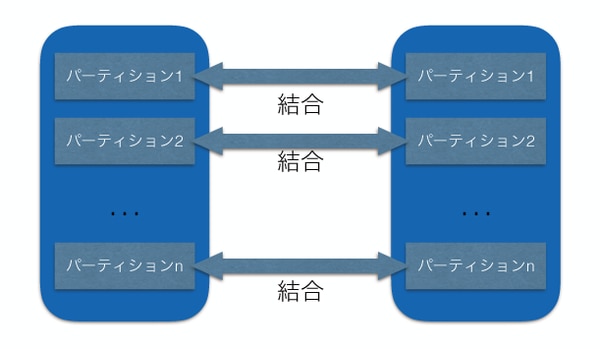
バージョン11以降ではこの点に改善がなされ、まずパーティションごとに結合を行うことが可能になりました。
図3
ただし、この機能を利用するためにはパラメータenable_partitionwise_joinをonに変更する必要があります(デフォルトはoffです)。
以下動作確認してみます。まずはパーティションワイズ結合を利用しない場合について見てみます。
-- 親テーブル定義
(PG12)=# CREATE TABLE members (id INT PRIMARY KEY, name TEXT) PARTITION BY HASH (id);
-- 子テーブル定義
(PG12)=# CREATE TABLE members_0 PARTITION OF members FOR VALUES WITH ( MODULUS 3, REMAINDER 0);
(PG12)=# CREATE TABLE members_1 PARTITION OF members FOR VALUES WITH ( MODULUS 3, REMAINDER 1);
(PG12)=# CREATE TABLE members_2 PARTITION OF members FOR VALUES WITH ( MODULUS 3, REMAINDER 2);
-- 親テーブル定義
(PG12)=# CREATE TABLE hobbies (member_id INT REFERENCES members(id), hobby TEXT) PARTITION BY HASH (member_id);
-- 子テーブル定義
(PG12)=# CREATE TABLE hobbies_0 PARTITION OF hobbies FOR VALUES WITH ( MODULUS 3, REMAINDER 0);
(PG12)=# CREATE TABLE hobbies_1 PARTITION OF hobbies FOR VALUES WITH ( MODULUS 3, REMAINDER 1);
(PG12)=# CREATE TABLE hobbies_2 PARTITION OF hobbies FOR VALUES WITH ( MODULUS 3, REMAINDER 2);
-- それぞれのパーティションに100000件のデータを投入
(PG12)=# INSERT INTO members SELECT i, 'ああああ' FROM generate_series(1, 100000) i;
(PG12)=# INSERT INTO hobbies SELECT i, md5(clock_timestamp()::text) FROM generate_series(1, 100000) i;
-- 統計情報を更新
(PG12)=# ANALYZE;
-- EXPLAIN ANALYZE を付与して実行計画を出力
(PG12)=# EXPLAIN ANALYZE SELECT * FROM members m JOIN hobbies h ON m.id = h.member_id;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=3974.00..10667.00 rows=100000 width=54) (actual time=40.370..149.312 rows=100000 loops=1)
Hash Cond: (h.member_id = m.id)
-> Append (cost=0.00..3168.00 rows=100000 width=37) (actual time=0.266..19.463 rows=100000 loops=1)
-> Seq Scan on hobbies_0 h (cost=0.00..895.85 rows=33585 width=37) (actual time=0.266..3.753 rows=33585 loo
ps=1)
-> Seq Scan on hobbies_1 h_1 (cost=0.00..893.94 rows=33494 width=37) (actual time=0.268..3.585 rows=33494 l
oops=1)
-> Seq Scan on hobbies_2 h_2 (cost=0.00..878.21 rows=32921 width=37) (actual time=0.471..3.698 rows=32921 l
oops=1)
-> Hash (cost=2138.00..2138.00 rows=100000 width=17) (actual time=40.011..40.012 rows=100000 loops=1)
Buckets: 65536 Batches: 2 Memory Usage: 2903kB
-> Append (cost=0.00..2138.00 rows=100000 width=17) (actual time=0.007..19.214 rows=100000 loops=1)
-> Seq Scan on members_0 m (cost=0.00..549.85 rows=33585 width=17) (actual time=0.007..3.519 rows=335
85 loops=1)
-> Seq Scan on members_1 m_1 (cost=0.00..548.94 rows=33494 width=17) (actual time=0.009..3.327 rows=3
3494 loops=1)
-> Seq Scan on members_2 m_2 (cost=0.00..539.21 rows=32921 width=17) (actual time=0.008..3.115 rows=3
2921 loops=1)
Planning Time: 0.296 ms
Execution Time: 157.063 ms
実行計画を見ると、まずそれぞれのパーティションを読み込み(実行計画のSeq Scan on .. の部分)、その出力をマージ(実行計画のAppendの部分)し、その結果をハッシュ結合(実行 計画のHash Joinの部分)していることがわかります。つまり、図1の形でクエリが実行されています。
次にパーティションワイズ結合を利用して同じクエリを実行してみます。
-- パーティションワイズ結合を有効化
(PG12)=# SET enable_partitionwise_join TO on;
(PG12)=# EXPLAIN ANALYZE SELECT * FROM members m JOIN hobbies h ON m.id = h.member_id;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
Append (cost=969.66..7431.00 rows=100000 width=54) (actual time=11.978..85.550 rows=100000 loops=1)
-> Hash Join (cost=969.66..2327.31 rows=33585 width=54) (actual time=11.977..28.977 rows=33585 loops=1)
Hash Cond: (h.member_id = m.id)
-> Seq Scan on hobbies_0 h (cost=0.00..895.85 rows=33585 width=37) (actual time=0.379..3.769 rows=33585 loo
ps=1)
-> Hash (cost=549.85..549.85 rows=33585 width=17) (actual time=11.506..11.506 rows=33585 loops=1)
Buckets: 65536 Batches: 1 Memory Usage: 2120kB
-> Seq Scan on members_0 m (cost=0.00..549.85 rows=33585 width=17) (actual time=0.008..5.299 rows=335
85 loops=1)
-> Hash Join (cost=967.62..2322.10 rows=33494 width=54) (actual time=9.581..24.873 rows=33494 loops=1)
Hash Cond: (h_1.member_id = m_1.id)
-> Seq Scan on hobbies_1 h_1 (cost=0.00..893.94 rows=33494 width=37) (actual time=0.245..3.280 rows=33494 l
oops=1)
-> Hash (cost=548.94..548.94 rows=33494 width=17) (actual time=9.250..9.250 rows=33494 loops=1)
Buckets: 65536 Batches: 1 Memory Usage: 2115kB
-> Seq Scan on members_1 m_1 (cost=0.00..548.94 rows=33494 width=17) (actual time=0.007..4.062 rows=3
3494 loops=1)
-> Hash Join (cost=950.72..2281.60 rows=32921 width=54) (actual time=8.831..23.695rows=32921 loops=1)
Hash Cond: (h_2.member_id = m_2.id)
-> Seq Scan on hobbies_2 h_2 (cost=0.00..878.21 rows=32921 width=37) (actual time=0.238..3.211 rows=32921 l
oops=1)
-> Hash (cost=539.21..539.21 rows=32921 width=17) (actual time=8.509..8.509 rows=32921 loops=1)
Buckets: 65536 Batches: 1 Memory Usage: 2088kB
-> Seq Scan on members_2 m_2 (cost=0.00..539.21 rows=32921 width=17) (actual time=0.025..3.717 rows=3
2921 loops=1)
Planning Time: 0.750 ms
Execution Time: 91.080 ms
同様に実行計画を見ると、同じパーティション境界同士(hobbies_0とmembers_0、hobbies_1とmembers_1、hobbies_2とmembers_2)をまず結合し(実行計画の3つのHash Joinの部分)、それらの出力をマージ(実行計画のAppendの部分)していることがわかります。これは、図2の形です。
enable_partitionwise_joinがデフォルト無効になっているのは、クエリ”実行”時の高速化は期待できるものの、実行”計画”作成時の考慮事項が増えるため、その分時間がかかってしまう恐れがあるためです。
上の例で示したように、enable_partitionwise_joinはSET文で変更できるパラメータなので、効果が確認できたクエリでのみ随時onにするという運用もよいでしょう。
パーティションワイズ結合は、等価結合時に結合対象のパーティションの境界が”完全に”一致する場合にしか現在は利用できません。例えば、年月をパーティションキーにしたレンジパーティショニングのパーティションを等価結合する場合、一方が1月, 2月, 3月分、もう片方が1月, 2月, 3月, 4月分でパーティションが分けられていると、4月分のパーティションがあるためにパーティションの境界が完全には一致しません。
このような結合では従来どおりそれぞれのパーティションを読み込んで、大きなテーブルを作った後で結合することになります。
(2)パーティションワイズ集約
集約についてもバージョン11以降ではパーティション単位で実行することが可能になりました。
この機能はパーティションワイズ結合と同様に、実行計画作成のコストが増えるため、デフォルトでは無効になっています。有効にするためにはパラメータ enable_partitionwise_aggregateをonに変更します。
先程作成したmembersテーブルについて、集約関数のCOUNT()を実行する場合の例を示します。
(PG12)=# EXPLAIN ANALYZE SELECT COUNT(*) FROM members;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=2388.00..2388.01 rows=1 width=8) (actual time=37.634..37.634 rows=1 loops=1)
-> Append (cost=0.00..2138.00 rows=100000 width=0) (actual time=0.022..28.826 rows=100000 loops=1)
-> Seq Scan on members_0 (cost=0.00..549.85 rows=33585 width=0) (actual time=0.021..6.625 rows=33585 loops=1)
-> Seq Scan on members_1 (cost=0.00..548.94 rows=33494 width=0) (actual time=0.012..5.425 rows=33494 loops=1)
-> Seq Scan on members_2 (cost=0.00..539.21 rows=32921 width=0) (actual time=0.016..4.832 rows=32921 loops=1)
Planning Time: 0.151 ms
Execution Time: 37.695 ms
デフォルトではmembersテーブルの各パーティションを読み込み(実行計画のSeq Scan on ..の部分)、その出力をマージ(実行計画のAppendの部分)した後に、件数を数えています (実行計画のAggreateの部分)。
-- パーティションワイズ集約を有効化
(PG12)=# SET enable_partitionwise_aggregate TO on;
SET
(PG12)=# EXPLAIN ANALYZE SELECT COUNT(*) FROM members;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=1888.05..1888.06 rows=1 width=8) (actual time=15.859..15.859 rows=1 loops=1)
-> Append (cost=633.81..1888.05 rows=3 width=8) (actual time=5.383..15.855 rows=3 loops=1)
-> Partial Aggregate (cost=633.81..633.82 rows=1 width=8) (actual time=5.382..5.383 rows=1 loops=1)
-> Seq Scan on members_0 (cost=0.00..549.85 rows=33585 width=0) (actual time=0.014..3.575 rows=33585 loops=1)
-> Partial Aggregate (cost=632.68..632.69 rows=1 width=8) (actual time=5.352..5.352 rows=1 loops=1)
-> Seq Scan on members_1 (cost=0.00..548.94 rows=33494 width=0) (actual time=0.007..3.380 rows=33494 loops=1)
-> Partial Aggregate (cost=621.51..621.52 rows=1 width=8) (actual time=5.118..5.118 rows=1 loops=1)
-> Seq Scan on members_2 (cost=0.00..539.21 rows=32921 width=0) (actual time=0.007..3.213 rows=32921 loops=1)
Planning Time: 0.145 ms
Execution Time: 15.923 ms
パーティションワイズ集約を有効化することで、各パーティションを読み込み後(実行計画のSeq Scan on ..の部分)、パーティションごとに件数を数えている(実行計画のPartial Aggreateの部分)ことがわかります。
今回のコラムでは、宣言的パーティショニングの進化について具体的な改善点を機能・性能の両面からいくつか確認しました。 次回はパラレルクエリについて見ていきたいと思います。
<参考資料>
(1) PostgreSQL 11新機能コラム 第1回「テーブル・パーティショニングが大幅アップデート」
(2) PostgreSQL 11新機能コラム 第2回「PostgreSQL11でのテーブル・パーティショニング機能の改善」
(3) Partitioning Improvements in PostgreSQL 11
(4) PostgreSQL 12: Partitioning is now faster
鳥越 淳(著者)
2008年頃からオープンソースソフトウェアの技術調査や案件導入に従事。PostgreSQLについては、PGConf.ASIA,PostgresConf USなどに登壇。共著に『PostgreSQL徹底入門 第4版』(翔泳社)がある。


