
PREPARATION
S3.1 SQL コマンド(パーティション)
3.140 NEW
テーブルをパーティションに分割することで得られることがある利点として、適切なものを3つ選びなさい。
- テーブルが必要とするディスク容量を小さくすることで、アクセス性能を向上させる。
- インデックスを小さくすることで、アクセス性能を向上させる。
- インデックス走査(index scan)の代わりに、パーティション内の全件走査(full scan)をすることで、アクセス性能を向上させる。
- 古いデータの一括削除、といった操作の処理時間を短縮する。
-
UPDATEによってデータがパーティション間を移動するときの処理が高速化される。
S3.1 SQL コマンド(スキーマ)
3.139
CREATE TABLESPACEコマンドでテーブルスペースts1を作成した。以下の説明から適切なものを2つ選びなさい。
- ts1は、作成時に接続していたデータベースからのみ利用可能で、データベースクラスタ内の他のデータベースからは利用できない。
- ts1にテーブルなどのオブジェクトを新規に作成するには、ts1について適切な権限が必要である。
- ts1に作成されたテーブルにアクセスするには、ts1について適切な権限が必要である。
- ts1は新規オブジェクトの作成専用で、既存のオブジェクトをts1に移動することはできない。
-
既存のテーブルについて、インデックスだけをts1に作成することができる。
S3.1 SQL コマンド(スキーマ)
3.138
show search_path の結果は以下の通りであるものとする。
=> show search_path;
search_path
-----------------
"$user", public
このとき、SELECT * FROM foo.bar; の実行について、最も適切な説明を2つ選びなさい。
- データベース foo 内にあるテーブル bar の内容を表示する。
- スキーマ foo 内にあるテーブル bar の内容を表示する。
- ユーザ foo が所有するテーブル bar の内容を表示する。
- 実行にあたり、fooのUSAGE権限とbar のSELECT権限の両方が必要である。
-
ユーザ foo が実行する場合は、SELECT * FROM bar; と必ず同じ結果になる。
S3.1 SQL コマンド(シーケンス)
3.137
あるユーザAが以下のSQLを実行した。
create sequence testseq;
select nextval('testseq');
このSELECT文は1を返した。以後の操作とその結果について、適切なものを3つ選びなさい。なお、このシーケンスへのアクセス権限は問題なく、また各選択肢に書かれている以外の操作はされていないものとする。
- 同じユーザAが引き続き select currval('testseq'); を実行したら1が返る。
- 別のユーザBがデータベースに接続し select currval('testseq'); を実行したら1が返る。
- 別のユーザCがデータベースに接続し、select nextval('testseq'); を実行したら2が返った。この直後にユーザAが select currval('testseq'); を実行したら2が返る。
- 別のユーザDがデータベースに接続し、選択肢CのユーザCと全く同じタイミングでselect nextval('testseq'); を実行したら3が返った。この直後にユーザCがselect currval('testseq'); を実行したら2が返る。
-
別のユーザEがデータベースに接続し、select setval('testseq', 10); select nextval('testseq'); を順次実行した。2つ目のSELECT文のnextvalは11を返す。
S3.1 SQL コマンド(マテリアライズド・ビュー)
3.135
ビューとマテリアライズド・ビューについての説明として間違っているものを1つ選びなさい。
- マテリアライズド・ビューにはインデックスを作成できるが、ビューにはインデックスを作成できない。
- マテリアライズド・ビューはデータ量に応じてディスク容量を消費するが、ビューはデータが増えてもディスク容量を消費しない。
- 同じ定義のビューとマテリアライズド・ビューに対して同じSELECT文を実行したら、必ず同じ結果が返る。
- 同じ定義のビューとマテリアライズド・ビューに対して、"SELECT * FROM ビュー名" を実行したら、通常はマテリアライズド・ビューからのSELECTの方が高速である。
- ビューは定義によってはINSERT/UPDATE/DELETEによる更新が可能なものもあるが、マテリアライズド・ビューに対してINSERT/UPDATE/DELETEを実行することはできない。
S3.1 SQL コマンド(ビュー)
3.134
ビューの説明として適切なものを2つ選びなさい。
- テーブルに対するのと全く同じようにSELECTを実行できる。
- データベースのバージョンおよびビューの定義にも依存するが、INSERTやUPDATEを実行できる場合がある。
- ビューの列に対してインデックスを作成できる。
- ビューの元になっているテーブルをDROP TABLEで削除すると、ビューが無効になる。
- ビューをDROP VIEWで削除するとき、CASCADEオプションを指定することで、ビューの元になっているテーブルも一緒に削除できる。
S3.1 SQL コマンド(インデックス)
3.133
次の手順でテーブルxとyを作成した。自動的にインデックスが作成されるのはどの列か。すべて答えなさい。
create table x (a integer primary key, b integer unique, c varchar(50) not null);
create table y (d integer primary key, e integer references x(b), f integer check
(f > 0));
- テーブルxの列a
- テーブルxの列b
- テーブルxの列c
- テーブルyの列d
- テーブルyの列e
- テーブルyの列f
S3.1 SQL コマンド(テーブル定義)
3.132
列idを主キーとするテーブルtestを作成する構文として正しいものを2つ選びなさい。
- create table test (primary key id integer, val varchar(50));
- create table test (id integer primary key, val varchar(50));
- create table test (id integer, val varchar(50), constraint id primary key);
- create table test (id integer, val varchar(50), primary key (id));
- create table test (id integer, val varchar(50), primary key = id);
S3.1 SQL コマンド(データ型)
3.131
PostgreSQLでテーブルに使用できるデータ型について正しいものを2つ選びなさい。
- integer型は4バイトの整数である。
- unsigned int型を使用して非負の整数を扱うことができる。
- long int型を利用して8バイトの整数を扱うことができる。
- byte型を利用して1バイトの整数を扱うことができる。
- numeric型は小数点を含めて40桁以上の10進数を扱うことができる。
S3.1 SQL コマンド(DELETE文)
3.130
DELETE FROM table_name;
を実行した。何が起きるか?
- SQLの構文が間違っているのでエラーが発生する。
- データ削除のSQLとして受け付けられるものの、WHERE句に合致する行がないので、何も削除されない。
- データを削除して良いか問い合わせるプロンプトが表示される。
- テーブルtable_nameに含まれるすべての行が削除され、テーブルは空になる。
- テーブルtable_nameが削除される。
S3.1 SQL コマンドUPDATE文)
3.129
以下の一連のSQLを実行した。最後のsumが返す値は何か。
create table sample (id integer primary key, val integer);
insert into sample(id) values (1), (2), (3), (4), (5);
update sample set val = id;
update sample set val = val * 2 where id > 2;
update sample set val = val + 1 where val < 4;
select sum(val) from sample;
S3.1 SQL コマンド(INSERT 文)
3.128
以下の一連のSQLコマンドを実行した。最後のSELECT文がcountとして返す値は何か。

S3.1 SQL コマンド(SELECT 文)
3.127
以下は、売上日(sales_date)、担当者(sales_person)、売り上げ先(client)、品名(item)、売上金額(amount)などを記録するsales表の一部である。

売上金額の合計が100000より大きい担当者を一覧表示したい。以下のSELECT文の空欄x, yに入るキーワードはそれぞれ何か。
select sales_person from sales [x] sales_person [y] sum(amount) > 100000;
- GROUP BY
- HAVING
- JOIN
- ORDER BY
- WHERE
S3.1 SQL コマンド(SELECT 文)
3.126
部署IDと部署名を格納したdept表、従業員ID、従業員名、生年月日、部署IDを格納したemp表があり、それぞれ以下のような構造になっている。
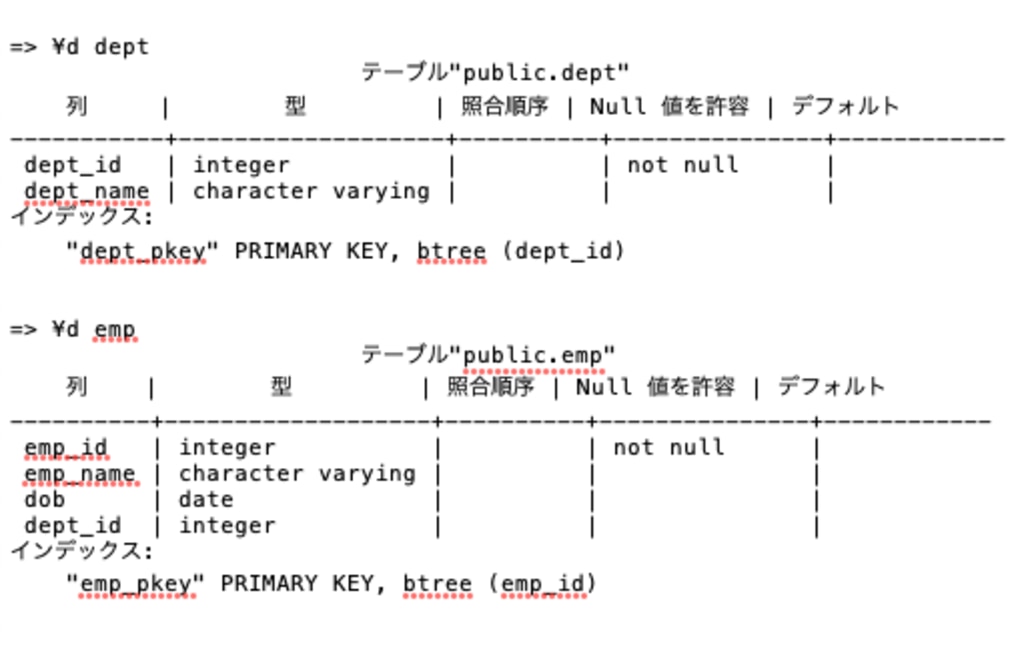
これらの表を結合し、従業員の一覧を表示するときに部署名を表示できるようにするSELECT文として適切なものを3つ選びなさい。
- select * from emp, dept join dept_id;
- select * from emp e, dept d where e.dept_id = d.dept_id;
- select * from emp natural join dept;
- select * from emp join dept using (dept_id);
- select * from emp e join dept d where e.dept_id = d.dept_id;
S3.1 SQL コマンド(SELECT 文)
3.125
現在時刻を調べるためにpsqlを使って select current_timestamp; を実行したら、
current_timestamp
-------------------------------
2021-02-26 22:31:02.311235+09
(1 行)
という結果になったが、これを select current_timestamp from x; としたら
current_timestamp
-------------------
(0 行)
という結果になった。from xを指定したときに現在時刻が表示されない理由として最も適切なものを選びなさい。
- テーブルxが存在しない。
- テーブルxに対するSELECT権限がない。
- テーブルxにcurrent_timestampという列がない。
- テーブルxは存在するがデータが1行も入っていない。
- current_timestampを取得するときにfrom句を指定してはいけない。
S3.3 トランザクションの概念(デッドロック)
3.124
デッドロックを回避する方策として適切なものを3つ選びなさい。
- 個々のトランザクションがなるべく短時間で終わるようにする。
- ロックを獲得したら、なるべく長時間それを保持する。
- 多数のトランザクションがなるべく同時に実行されるようにする。
- 複数のリソースをロックする際、ロックを獲得する順序を各トランザクションで同じにする。
- 不要なロックを取得しないようにする。
S3.3 トランザクションの概念(トランザクション分離レベル)
3.123
PostgreSQLのトランザクション分離レベルについて、誤っている説明を1つ選びなさい。
- トランザクションの開始時に SET TRANSACTION ISOLATION LEVEL xxx などとすることで、トランザクション分離レベルを指定できる。
- トランザクション分離レベルとしてSERIALIZABLE, REPEATABLE READ, READ COMMITTED, READ UNCOMMITTED の4種類のいずれかを指定できる。
- デフォルトのトランザクション分離レベルは設定パラメータで指定するが、設定パラメータで指定されていないときはREPEATABLE READがデフォルトとなる。
- REPEATABLE READは反復不能読み取りを防ぐ分離レベルだが、ファントムリードも発生しなくなる。
- READ UNCOMMITTEDは確定していないデータの読み取りを許容する分離レベルだが、ダーティーリードは発生しない。
S3.3 トランザクションの概念(トランザクションの構文)
3.122
以下の一連のSQLを実行した。最後のSELECT文が返す値は何か。
create table test(id integer);
begin;
insert into test(id) values(1);
commit;
begin;
insert into test(id) values(2);
savepoint x;
insert into test(id) values(3);
rollback to x;
insert into test(id) values(4);
commit;
begin;
insert into test(id) values(5);
savepoint x;
insert into test(id) values(6);
rollback;
commit;
select sum(id) from test;
S3.2 組み込み関数(文字列演算子・述語)
3.121
PostgreSQLでの文字列の処理について適切なものを3つ選びなさい。
- 文字列を結合するには || を使うことができる。例えば 'abc' || 'xyz' は 'abcxyz' となる。
- 文字列を結合するには + を使うことができる。例えば 'abc' + 'xyz' は 'abcxyz' となる。
- 文字列の比較に使う LIKE は大文字と小文字を区別しないので、例えば 'ABC' LIKE 'abc' は真となる。
- LIKEによる文字列比較では、_ と % がワイルドカードであり、例えば 'abcde' LIKE 'a_c%' は真となる。
- 正規表現との比較をするSIMILAR TOがサポートされているが、POSIX正規表現とは異なり、_ と % がワイルドカードである。例えば 'abcde' SIMILAR to 'a_c%' は真となる。
企業の基幹システムや業務システム、AIなどの
新領域での「PostgreSQL」の採用が拡大している中、
昇格・昇給・就職・転職に必ず役立つ認定です
OSS-DBの受験対策
受験の学習をサポートする情報や対策に役立つ情報をご紹介

例題解説
例題のアーカイブを試験ごとにまとめています。OSS-DB技術者認定試験の学習にお役立てください

学習教材・教育機関ご紹介
OSS-DB認定教材や教育機関について詳しくご説明いたします。

無料技術解説セミナー
受験準備をされていらっしゃる方々を対象に、無料技術解説セミナーの日程をお知らせしています。

OSS-DB道場
OSS-DBやPostgreSQLの知識、技術を得るために役立つ情報の紹介やコラムを公開しています。



LPI-Japan Platinum Sponsors



















© EDUCO All Rights Reserved.